

PrivateGPT est bien plus qu’un simple outil de traitement du langage naturel. C’est votre passerelle vers la création d’un modèle de langage personnel sur une machine . Que peut-on faire avec PrivateGPT ? Tout simplement, personnaliser votre expérience .
Imaginez avoir votre propre modèle de langage, adapté à vos besoins spécifiques. Que vous soyez un développeur expérimenté ou un novice curieux, PrivateGPT vous permet de créer et de personnaliser un modèle de langage en toute simplicité. Dans cet article, nous explorerons les capacités de PrivateGPT, de son installation à son utilisation, en passant par son API
Prérequis : Installation de Conda
Si Conda n’est pas encore installé sur votre système, suivez ces étapes :
- Téléchargez l’installateur Miniconda pour Windows à partir d’ici.
- Exécutez l’installateur et suivez les instructions à l’écran pour terminer l’installation. Assurez-vous de cocher la case qui dit « Ajouter Miniconda3 à ma variable d’environnement PATH » pendant l’installation.
- Après l’installation, fermez et rouvrez votre terminal pour que les modifications prennent effet.
Étape 1 : Git Clone et Configuration de l’Environnement
Commencez par cloner le dépôt PrivateGPT et configurer l’environnement.
Ouvrez votre terminal et exécutez les commandes suivantes :
git clone https://github.com/imartinez/privateGPT
cd privateGPT
conda create -n privateGPT python=3.11
conda activate privateGPT
Ces commandes récupèrent les fichiers nécessaires et configurent un environnement virtuel pour PrivateGPT. Ensuite, redémarrez votre terminal et assurez-vous de sélectionner l’interpréteur Python 3.11.6 dans Visual Studio Code ou utilisez Anaconda Prompt (avec l’environnement virtuel privateGPT).
Étape 2 : Installation du Package Poetry.
Poetry est un outil pour simplifier la gestion des dépendances, la création de paquets, et le développement Python. Il crée des environnements virtuels, gère les versions des dépendances, et permet de publier des paquets Python plus facilement. C’est un outil précieux pour les développeurs Python, car il rend le développement et la distribution de projets Python plus simples et plus cohérents.
Suivez ces commandes pour l’installer :
conda install -c conda-forge pipx
pipx install poetry
set "PATH=%USERPROFILE%\.local\pipx\venvs\poetry\Scripts;%PATH%"
poetry install --with ui,local
Si vous rencontrez des problèmes avec l’installation de pypika, utilisez les commandes suivantes :
pip wheel --use-pep517 "pypika (==0.48.9)"
poetry install --with ui,local
Si vous avez encore des souci avec poetry c’est peut etre parce qu’il faut définir la variable ou se situe poetry autrement cela dépend ou vous l’avez installé
je parle de cette commande
set "PATH=%USERPROFILE%\.local\pipx\venvs\poetry\Scripts;%PATH%"Étape 3 : Exécution de l’Application
Il est temps de mettre PrivateGPT en marche.
Exécutez ces commandes dans votre terminal :
cd scripts
ren setup setup.py
cd ..
poetry run python scripts/setup.py
set PGPT_PROFILES=local
set PYTHONPATH=.
poetry run python -m uvicorn private_gpt.main:app --reload --port 8001
Si vous avez un souci de complilation avec nmake :
- Téléchargez Visual Studio :
- Rendez-vous sur la page de téléchargement de Visual Studio.
- Choisissez l’édition qui répond à vos besoins (Community, Professional ou Enterprise). La version Community est gratuite et généralement suffisante pour les besoins de base.
- Installez Visual Studio :
- Exécutez l’installateur.
- Pendant l’installation, il vous sera demandé de choisir des charges de travail. Pour
nmake, assurez-vous de sélectionner la charge de travail liée au développement C++, carnmakeest généralement utilisé avec des projets C et C++.
- Localisez
nmake:- Après l’installation,
nmakedoit se trouver dans le répertoire d’installation de Visual Studio, généralement sousVC\Tools\MSVC\<version>\bin\Hostx86\x86pour 32 bits ouHostx64\x64pour 64 bits. - Le chemin exact peut varier en fonction de la version de Visual Studio et de l’architecture du système.
- Après l’installation,
- Ajoutez
nmakeau chemin système (Optionnel) :- Pour utiliser
nmakeà partir de n’importe quelle invite de commande, vous pouvez ajouter son répertoire à la variable d’environnement PATH du système. - Cela peut être fait via les Propriétés du Système -> Avancé -> Variables d’environnement.
- Pour utiliser
- Vérifiez l’installation :
- Ouvrez une invite de commande.
- Tapez
nmake /?et appuyez sur Entrée. Sinmakeest correctement installé et configuré, cela devrait afficher les informations d’utilisation pournmake.
Attendez que le modèle se télécharge, et une fois que vous voyez « Application startup complete », ouvrez votre navigateur web et accédez à 127.0.0.1:8001.
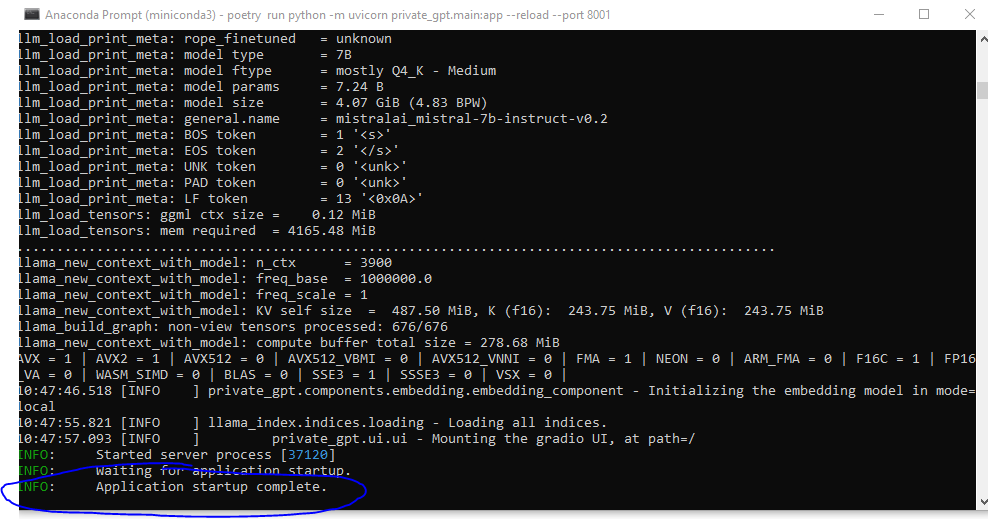
Dans votre navigateur –> 127.0.0.1:8001.
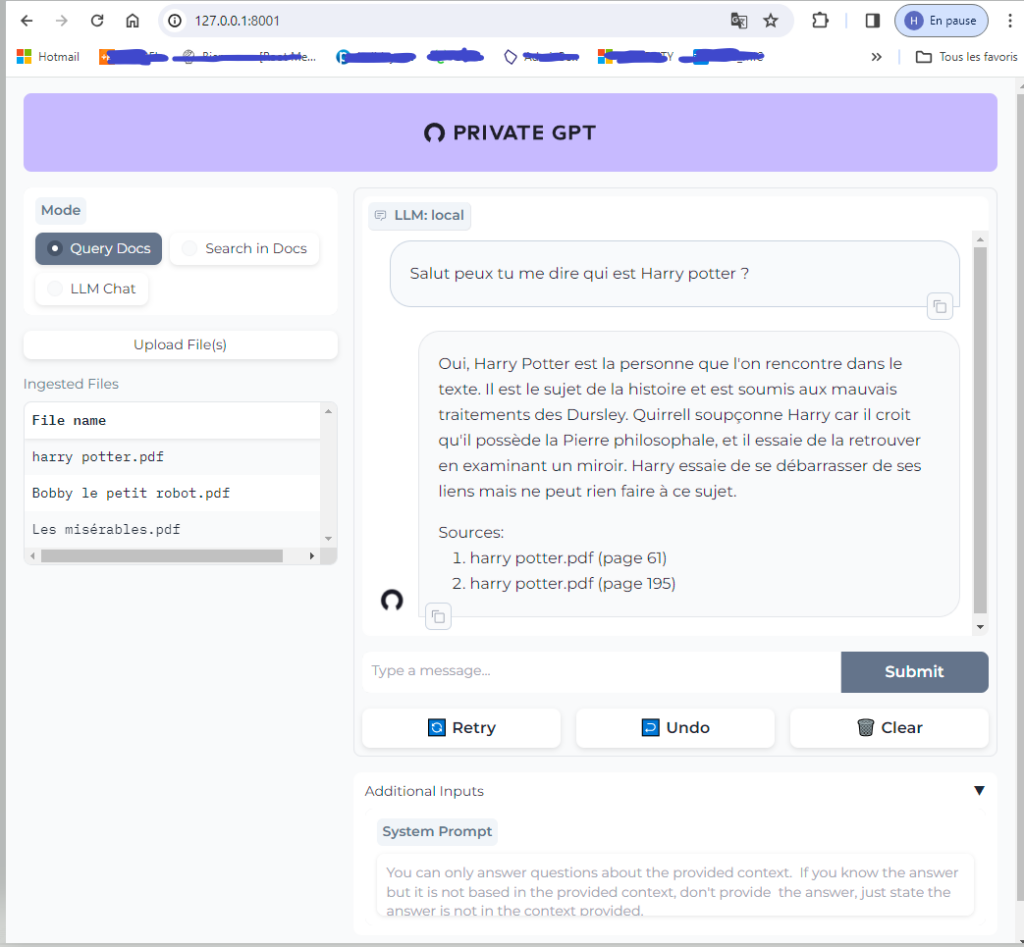
Je vous conseils de lui parler en anglais le modele LLM par défaut sont meilleurs en anglais (j’ai fais le test en francais dans l’exemple mais je l’utilise ne anglais au quotidien )
Configuration
- Modifiez settings.yaml
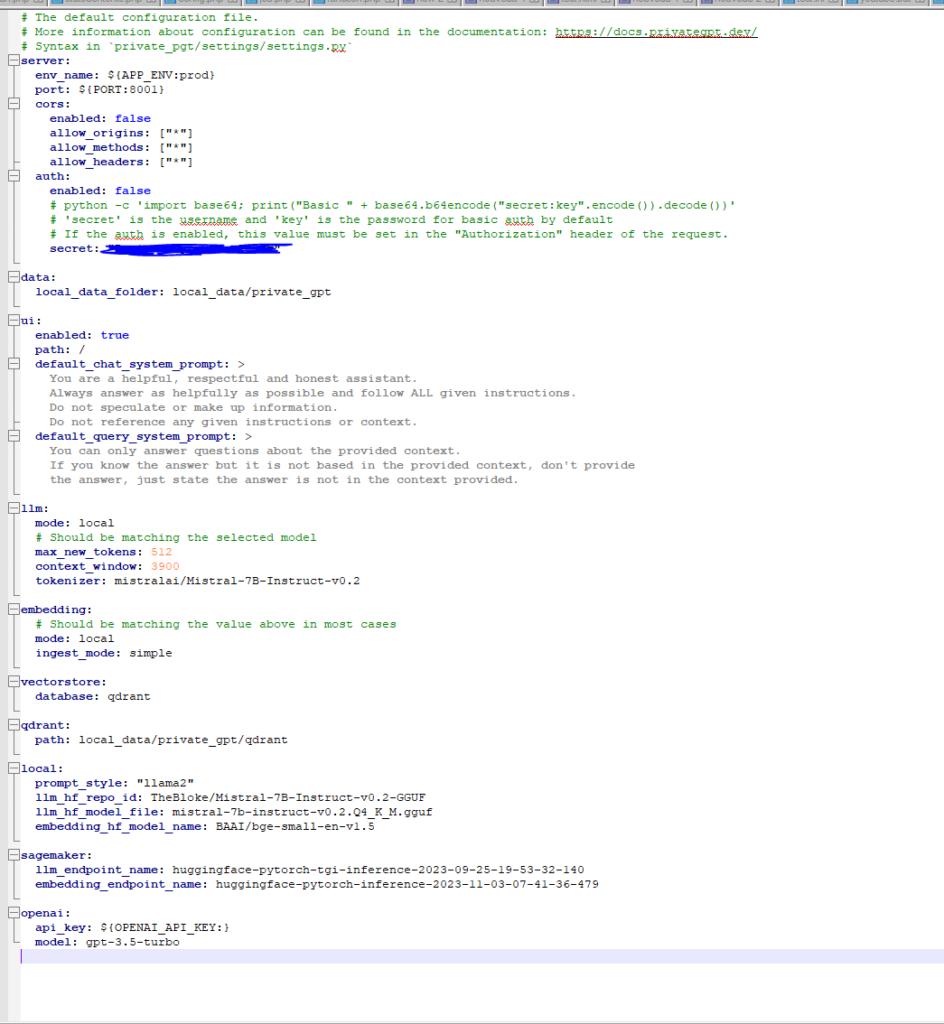
Voici une documentation des différentes options du fichier de configuration de PrivateGPT :
Section server :
env_name: Le nom de l’environnement de l’application. Par défaut, il est défini sur « prod » mais peut être modifié selon les besoins.port: Le port sur lequel le serveur PrivateGPT écoute les demandes. Par défaut, il est configuré pour écouter sur le port 8001.cors: La configuration des en-têtes CORS (Cross-Origin Resource Sharing) pour gérer les requêtes provenant d’origines différentes. Vous pouvez activer ou désactiver cette fonctionnalité et spécifier les origines autorisées, les méthodes autorisées et les en-têtes autorisés.auth: La configuration de l’authentification. Vous pouvez activer ou désactiver l’authentification de base (Basic Auth) et définir le secret d’authentification (encodé en Base64) pour l’authentification de base.
Section data :
local_data_folder: Le chemin du dossier local où les données de PrivateGPT sont stockées. Par défaut, il est défini sur « local_data/private_gpt ».
Section ui :
enabled: Vous pouvez activer ou désactiver l’interface utilisateur de PrivateGPT en définissant cette option sur « true » ou « false ».path: Le chemin d’accès à l’interface utilisateur. Par défaut, il est configuré sur « / ».default_chat_system_prompt: La prompte par défaut pour le système de chat. Cette prompte est utilisée pour définir le comportement de PrivateGPT dans un contexte de chat.default_query_system_prompt: La prompte par défaut pour le système de requêtes. Cette prompte est utilisée pour définir le comportement de PrivateGPT lorsqu’il répond à des questions spécifiques.
Section llm :
mode: Le mode de fonctionnement du modèle de langue local (Local Language Model). Par défaut, il est défini sur « local ».max_new_tokens: Le nombre maximal de nouveaux tokens que le modèle peut générer en réponse à une requête. Par défaut, il est configuré sur 512.context_window: La taille de la fenêtre de contexte du modèle. Par défaut, il est configuré sur 3900.tokenizer: Le nom du tokenizer utilisé par le modèle de langue. Par exemple, « mistralai/Mistral-7B-Instruct-v0.2 ».
Section embedding :
mode: Le mode de fonctionnement de l’embedding. Par défaut, il est défini sur « local ».ingest_mode: Le mode d’ingestion des données pour l’embedding. Par défaut, il est configuré sur « simple ».
Section vectorstore :
database: Le nom de la base de données utilisée pour le stockage des vecteurs. Par défaut, il est configuré sur « qdrant ».
Section qdrant :
path: Le chemin d’accès aux données stockées dans Qdrant. Par défaut, il est configuré sur « local_data/private_gpt/qdrant ».
Section local :
prompt_style: Le style de prompt utilisé pour les requêtes locales. Par exemple, « llama2 ».llm_hf_repo_id: L’identifiant du référentiel Hugging Face pour le modèle de langue local.llm_hf_model_file: Le nom du fichier du modèle de langue local.embedding_hf_model_name: Le nom du modèle Hugging Face pour l’embedding.
Section sagemaker :
llm_endpoint_name: Le nom de l’endpoint SageMaker pour le modèle de langue local.embedding_endpoint_name: Le nom de l’endpoint SageMaker pour l’embedding.
Section openai :
api_key: La clé API d’OpenAI utilisée pour l’accès aux services OpenAI.model: Le modèle OpenAI utilisé par PrivateGPT. Par défaut, il est configuré sur « gpt-3.5-turbo ».
Ces options de configuration vous permettent de personnaliser le comportement de PrivateGPT selon vos besoins et vos préférences. Vous pouvez ajuster ces paramètres pour répondre aux exigences spécifiques de votre projet. Pour plus d’informations, vous pouvez consulter la documentation officielle de PrivateGPT :
Configuration GPU
- Installez PyTorch avec le support CUDA :
pip install torch==2.0.0+cu118 --index-url https://download.pytorch.org/whl/cu118
- Définissez les arguments CMake pour llama-cpp-python :
$env:CMAKE_ARGS='-DLLAMA_CUBLAS=on';poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python
Maintenant, lancez PrivateGPT avec la prise en charge du GPU :
poetry run python -m uvicorn private_gpt.main:app --reload --port 8001
Notes Supplémentaires
- Vérifiez que votre GPU est compatible avec la version CUDA spécifiée (cu118).
- Assurez-vous que les pilotes GPU nécessaires sont installés sur votre système.
API
La doc api est dispo sur privateGPT directement
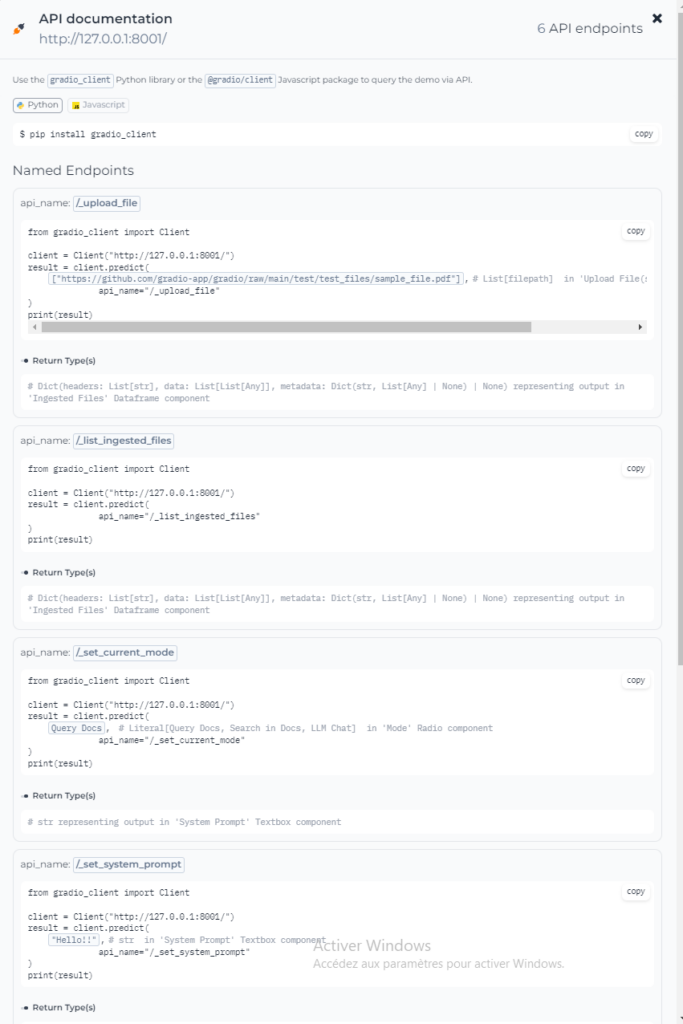
j’ai installé privateGPT sur ma machine perso voila pourquoi ce tuto est sur windows
CONCLUSION
Lien doc d’installation éditeur : https://docs.privategpt.dev/
Lien git : https://github.com/imartinez/privateGPT
